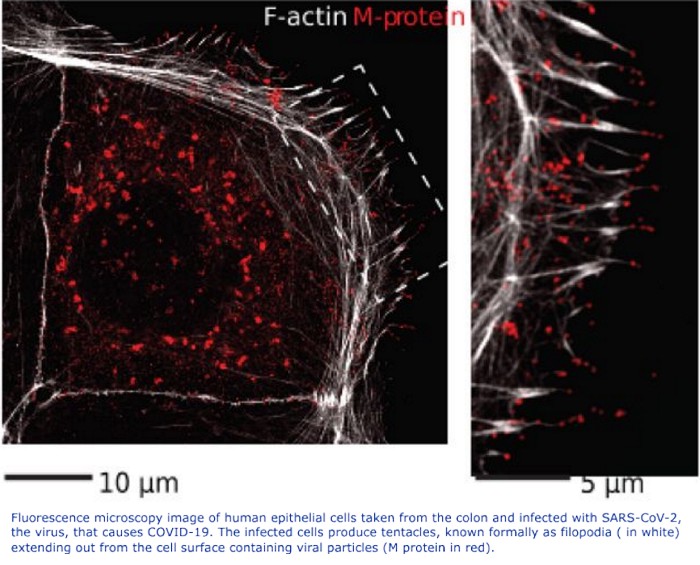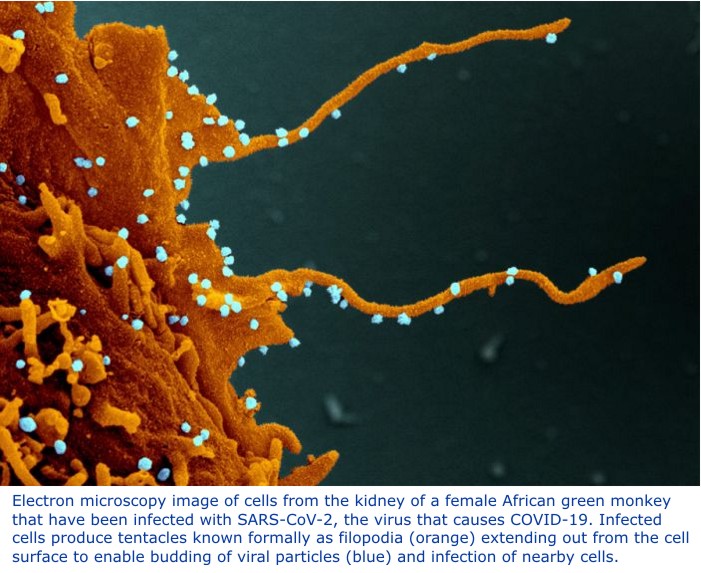
Written By: Hollis Lynch (a Black Trinidadian): Professor Emeritus of History, Columbia University.
African Americans, one of the largest of the many ethnic groups in the United States. African Americans are mainly of African ancestry, but many have non-black ancestors as well. African Americans are largely the descendants of slaves—people who were brought from their African homelands by force to work in the New World. Their rights were severely limited, and they were long denied a rightful share in the economic, social, and political progress of the United States. Nevertheless, African Americans have made basic and lasting contributions to American history and culture.
At the turn of the 21st century, more than half the country’s more than 36 million African Americans lived in the South; 10 Southern states had black populations exceeding 1 million. African Americans were also concentrated in the largest cities, with more than 2 million living in New York City and more than 1 million in Chicago. Detroit, Philadelphia, and Houston each had a black population between 500,000 and 1 million.
| Keeping in mind that Blacks have never participated fully in ANY census, and these are Albino people figures: As of the 2010 census, L.A. County had a population of about 1 million Blacks, Baltimore MD with about 400,000; Ohio has at least three cities: Cleveland, Columbus, and Cincinnati with 200,000 or more in Black population. Milwaukee County is home to 240,203 African Americans| Every city in the United States has a sizable Black population, and like their rural cohorts, they do not like to tell the government where they are - except to participate in government welfare programs. Some cities have sued the federal government for UNDERCOUNTING Blacks, because Federal money for social programs is based on Census population figures. Our own estimates, based on the number of Blacks who came out to vote for Barack Obama, indicates that the actual population of Blacks in the United States is nearer 100 million. And the point of this divergence is to show how "So-called" educated Negroes may be the greatest impediment to truth, because they all seem to swallow the lies and bullshit of their Albino educators without critical review. |
As Americans of African descent reached each new plateau in their struggle for equality, they reevaluated their identity. The slaveholder labels of black and Negro (Spanish for black) were offensive, so they chose the euphemism colored when they were freed. Capitalized, Negro became acceptable during the migration to the North for factory jobs. Afro-American was adopted by civil rights activists to underline pride in their ancestral homeland, but black—the symbol of power and revolution—proved more popular. All these terms are still reflected in the names of dozens of organizations. To reestablish “cultural integrity” in the late 1980s, Jesse Jackson proposed African American, which—unlike some “baseless” color label—proclaims kinship with a historical land base. In the 21st century the terms black and African American both were widely used. Comment: Strangely it never occurred to them that there was a historical REASON why Black Americans were NOT called Africans.
The Albinos use of Schools and Media to Miseducate us.As an example of the Albinos duplicitous nature: in current times American Albinos constantly refer to Blacks as "Minorities". This is of course to instill the thought that Albinos are numerous and powerful. They use their monopoly over media to reinforce this by constantly showing images from all parts of the World of only other Albinos and their Mulattoes. Except for Africa, rarely are Blacks shown in international News Stories, or travelogs. But their Make-believe "Black free World" is just like their histories; pure fantasy. Here is another example of how the Albinos use their power over what we are taught to miseducate us: if you Google "What race has the largest population in the world?" The answer you are given is Quote: "The world's largest ethnic group is Han Chinese". Notice they replaced "Ethnic Group" with "Race". That's like saying that Germans are the largest racial population. Germans are of course NOT a Race! Just like Han Chinese are NOT a Race! Han Chinese, Japanese, Koreans, Twainese, Cambodians, Thais, Vietnamese, etc. are of the "MONGOL" Race. All together Mongols account for a little less that Two Billion people. Do this: Google – “White World Population” Being very care with the syntax, remember you are asking an Albino source for truth. Naturally they will find any number of ways to lie to you if you use the wrong search words. Answer from Wikipedia section titled “White People”: 850,000,000+ (which is about) 11.5% of the total world population (world population of 7.5 - 7.7 billion). Facts and Figures: The current population of Japan is 126,766,566 as of 2019, based on Worldometers elaboration of the latest United Nations data. For a total East-Asian Mongol population of 1,637,452,415 people: which is about 21% of the Human population.The current world population is 7.7 billion as of September 2019 according to the most recent United Nations estimates elaborated by Worldometers. Here is the “Cold Water” of reality Albinos and Mongols: “YOUR” 21% + 11.5% = 32.5% of the Human population.
|
Continuing Professor Hollis Lynch’s article:
The early history of blacks in the Americas
Africans assisted the Spanish and the Portuguese during their early exploration of the Americas. In the 16th century some black explorers settled in the Mississippi valley and in the areas that became South Carolina and New Mexico. The most celebrated black explorer of the Americas was Estéban, who traveled through the Southwest in the 1530s. The uninterrupted history of blacks in the United States began in 1619, when 20 Africans were landed in the English colony of Virginia. These individuals were not slaves but indentured servants—persons bound to an employer for a limited number of years—as were many of the settlers of European descent (whites). By the 1660s large numbers of Africans were being brought to the English colonies. In 1790 blacks numbered almost 760,000 and made up nearly one-fifth of the population of the United States. Comment: Pay attention, this number will be debunked by the author himself just one paragraph down.
Attempts to hold black servants beyond the normal term of indenture culminated in the legal establishment of black chattel slavery in Virginia in 1661 and in all the English colonies by 1750. Black people were easily distinguished by their skin color (the result of evolutionary pressures favoring the presence in the skin of a dark pigment called melanin in populations in equatorial climates) from the rest of the populace, making them highly visible targets for enslavement. Moreover, the development of the belief that they were an “inferior” race with a “heathen” culture made it easier for whites to rationalize black slavery. Enslaved blacks were put to work clearing and cultivating the farmlands of the New World. Of an estimated 10 million Africans brought to the Americas by the slave trade, about 430,000 came to the territory of what is now the United States. Comment: We must all have sympathy for Professor Hollis Lynch; it is very hard to keep all of the Albino man’s lies in order.
The overwhelming majority were taken from the area of western Africa stretching from present-day Senegal to Angola, where political and social organization as well as art, music, and dance were highly advanced. On or near the African coast had emerged the major kingdoms of Oyo, Ashanti, Benin, Dahomey, and the Congo. In the Sudanese interior had arisen the empires of Ghana, Mali, and Songhai; the Hausa states; and the states of Kanem-Bornu. Such African cities as Djenné and Timbuktu, both now in Mali, were at one time major commercial and educational centers.
With the increasing profitability of slavery and the slave trade, some Africans themselves sold captives to the European traders. The captured Africans were generally marched in chains to the coast and crowded into the holds of slave ships for the dreaded Middle Passage across the Atlantic Ocean, usually to the West Indies. Shock, disease, and suicide were responsible for the deaths of at least one-sixth during the crossing. In the West Indies the survivors were “seasoned”—taught the rudiments of English and drilled in the routines and discipline of plantation life.
Professor Hollis Lynch works for Columbia University.
Professor Henry Louis Gates works for Harvard University.
Professor Ben Vinson III is Dean of Columbian College, G.W. University
|
 |
On to Genetics and Ancestry DNA Tests
https://www.nytimes.com/2014/12/25/science/23andme-genetic-ethnicity-study.html
Now from that statement, a logical person would assume the Europeans have UNIQUE Genes that would of course be "WHITE" genes, and Blacks would have UNIQUE genes, which of course would be "BLACK" genes. Strange that the 23andMe company didn't mention what those "UNIQUE" genes were.
Moving on; the AncestryDNA Company has a commercial running in the U.S. where a young Black woman (Lyn Johnson) declares that the company tested her genes and found that she was 26% Nigerian. Here again, you would expect that Nigerians have UNIQUE genes which allows us to tell them from all other African people. And here again, the company didn't mention what those "UNIQUE" genes were. But once again, RHWW rides to the rescue - if you will allow us to help.
 |
Nigeria has more than 500 ethnic groups, with varying languages and customs, creating a country of rich ethnic diversity. The largest ethnic groups are the Hausa, Yoruba, Igbo and Fulani: they together account for more than 70% of the population. While the Urhobo-Isoko, Edo, Ijaw, Kanuri, Ibibio, Ebira, Nupe, Gwari, Jukun, Igala, Idoma and Tiv comprise between 25 and 30%; other minorities make up the remaining 5%.
Hausa - According to a Y-DNA study by Hassan et al. (2008), about 47% of the Hausa in Niger and Cameroon have the following paternal lineages: 15.6% B, 12.5% A and 12.5% E1b1a. A small minority of around 4% are E1b1b clade bearers, a haplogroup which is most common in North Africa and the Horn of Africa.
Yoruba - 93.1% of these people are Haplogroup E-V38 (formerly E3a/ E1b1a).
Fulani - The paternal lineages of the Fula/Fulbe/Fulani tend to vary depending on geographic location. According to a study by Cruciani et al. (2002), around 90% of Fulani individuals from Burkina Faso carried haplotype 24, which corresponds with the haplogroup E1b1a that is common in West Africa. The remainder belonged to haplotype 42/haplogroup E-M33 (Now E-M132). Both of these clades are today most frequent among Niger-Congo-speaking populations, particularly those inhabiting Senegal. Similarly, 53% of the Fulani in northern Cameroon bore haplogroup E-M33, with the rest mainly carrying 12% haplogroup A and 6% haplogroup E1b1a). A minority carried the T (18%) and R-M173 (12%). Mulcare et al. (2004) observed a similar frequency of haplogroup R1 subclades in their Fulani samples from Cameroon (18%).
A study by Hassan et al. (2008) on the Fulani in Sudan observed a significantly higher occurrence of R-M173 (53.8%). The remainder belonged to various haplogroup E1b1b subclades, including 34.62% E-M78 and 27.2% E-V22. Bučková et al. (2013) similarly observed significant frequencies of the haplogroups R1b and E1b1b in their pastoralist Fulani groups from Niger. E1b1b attained its highest frequencies among the local Fulani Ader (60%) and R1b among the Fulani Zinder (~31%). This was in sharp contrast to most of the other Fulani pastoralist groups elsewhere, including those from Burkina Faso, Cameroon, Mali and Chad. All of these latter Fulani communities instead bore over 75% West African paternal haplogroups.
Igbo - 89.3% of these people are Haplogroup E-V38 (formerly E3a/ E1b1a).
No genetic information is available for the Urhobo-Isoko, Edo and the other small minority groups: though certain Ijaw People claim to have been tested with Y-DNA R1b1b2a1a1. According to one study 6% in the Kanuri share genes with the Tuareg: which is pretty meaningless.
__________________________________________________________________
 |
__________________________________________________________________
First and foremost: There is no such a thing as "White" genes! The reason for that is because a natural Modern Human is a "Black Skinned" African who evolved from earlier Homo-sapiens from about 400,000 years ago. Albinos, such as the European, evolved just 8,000 to 12,000 years ago, as a result of them foolishly breeding among themselves (which can only produce other Albinos), rather than as normally done - with a healthy Black only, which will produce mulattoes of various shades.
TYR Gene - The official name of this gene is “tyrosinase.” - it causes Oculocutaneous albinism type I (OCA1)
OCA2 gene (formerly called the P gene) - The official name of this gene is “oculocutaneous albinism II.”
TYRP1 gene - The official name of this gene is “tyrosinase-related protein 1.” It causes Oculocutaneous albinism type 3 (OCA3)
SLC45A2 gene - The official name of this gene is “solute carrier family 45, member 2.” It causes Oculocutaneous albinism type 4 (OCA4)
SLC24A5 - gene has been associated with differences in skin pigmentation.
As of today, there are four more types: for a total of eight different types of Albinism identified. The remainder of this page, and the many other pages in this section, provide great data details to refute the Nonsense of White genes. For those who prefer the say-so of Albinos, CBS 60 minutes did a program called: Rebuilding the Family Tree: A CBS News expose of the "Wildly" false claims of Genetic Testers. Here is the link: https://www.youtube.com/watch?v=vWXbXfVr07g
 |
This early sample is known as the Cambridge Reference Sequence (CRS). An updated reference sequence was subsequently published and samples are now compared to the revised Cambridge Reference Sequence (rCRS). A list of single-nucleotide polymorphisms (SNPs) is returned. The relatively few "mutations" or "transitions" that are found are then reported simply as differences from the CRS
Haplogroup H (mtDNA) Undifferentiated haplogroup H has been found among Palestinians (14%), Syrians (13.6%), Druze (10.6%), Iraqis (9.5%), Somalis (6.7%), Egyptians (5.7% in El-Hayez; 14.7% in Gurna), Saudis (5.3–10%), Soqotri (3.1%), Nubians (1.3%), and Yemenis (0–13.9%). H2, H6 and H8
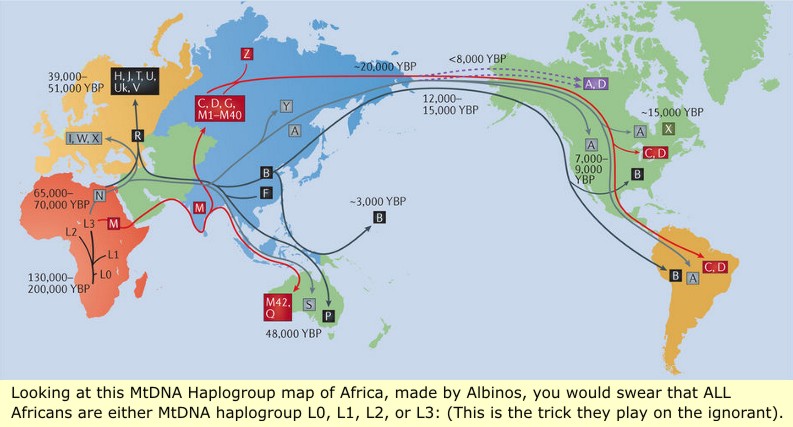
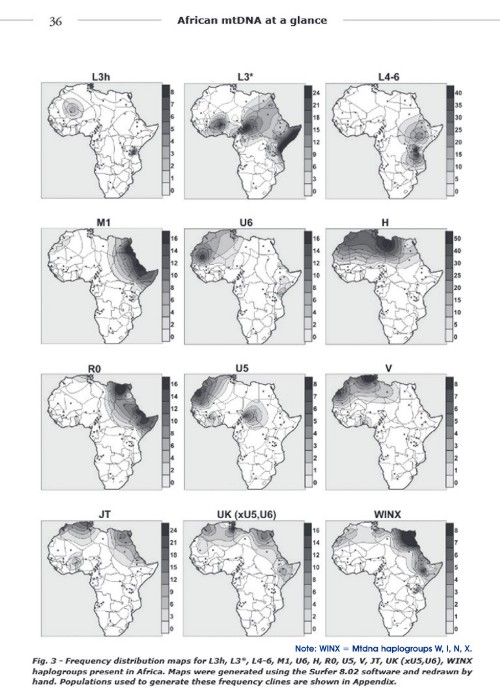
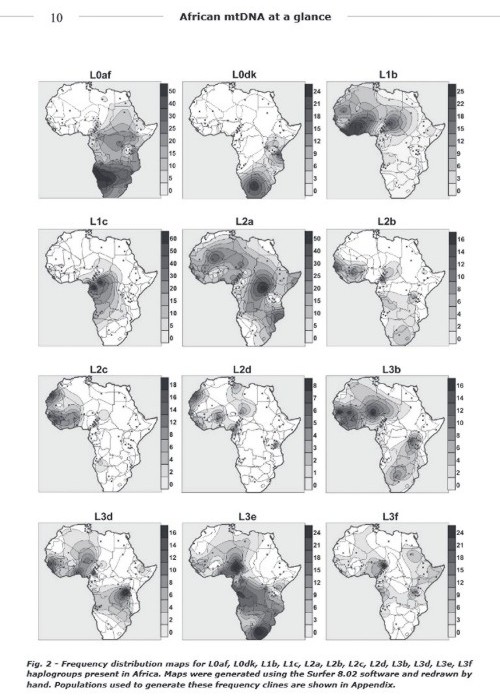
THESE ARE "SOME" OF THE ACTUAL MtDNA HAPLOGROUPS IN AFRICA!(Just a small sampling of Africans have been tested for DNA).
As a point of interest, the "OLDEST" DNA extracted from Human remains in Europe is the MtDNA haplogroup "U2" and Y-DNA "C" taken from the remains of this Black African Man whom the Albinos have tried mightily to make appear Caucasian.
IN ITALY:In 2016 it was found that a 31-35 thousand years old human from the cave named Paglicci 33 (Rignano Garganico (FG, Apulia, Italy) carried Y-DNA haplogroup I and mtDNA haplogroup U8c.
|
Below is a condensed explanation of Genetics andDNA that we hope everyone will understand:if not please let us know.
We are going from Soup to Nuts..
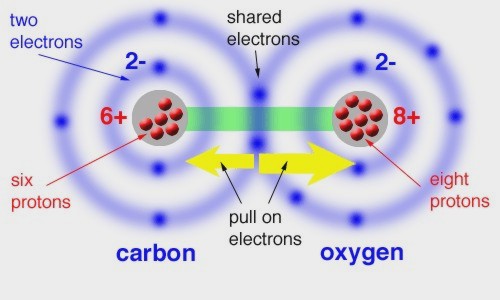
A quark is a type of elementary particle and a fundamental constituent of matter. Quarks combine to form composite particles called hadrons, the most stable of which are protons and neutrons, the components of atomic nuclei. Quarks have not been directly observed but theoretical predictions based on their existence have been confirmed experimentally. The Atom is the smallest unit into which matter can be divided without the release of electrically charged particles. It also is the smallest unit of matter that has the characteristic properties of a chemical element. As such, the atom is the basic building block of chemistry. When the atom was discovered, it was thought indivisible, until it was split to reveal protons, neutrons and electrons inside. These too, seemed like fundamental particles, before scientists discovered that protons and neutrons are made of three quarks each. An element is a substance that is made entirely from one type of atom. For example, the element hydrogen is made from atoms containing just one proton and one electron. Molecules are formed when two or more atoms bond together. If molecules contain atoms of different elements, that substance is known as a compound. "Molecules" are individual assemblies of atoms held together by covalent bonds. "Elements" are substances composed of atoms with all the same atomic number. "Elements" typically contrasts with "compounds," substances composed of atoms with different atomic numbers in some specific proportion (e.g. NaCl, H2SO4, CO2). Human Body Elements Almost 99% of the mass of the human body is made up of six elements: oxygen, carbon, hydrogen, nitrogen, calcium, and phosphorus. Only about 0.85% is composed of another five elements: potassium, sulfur, sodium, chlorine, and magnesium. With the most abundant being oxygen (65% by mass), carbon (18%), hydrogen (10%), nitrogen (3%), calcium (1.4%) and phosphorous (1.1%),”
The two most abundant elements in the Human body
Genes/DNA
Recombination and Estimating the Distance Between Genes
Finally, for two genes that are right next to each other on the chromosome, crossing over will be a very rare event. Two types of gametes are possible when following genes on the same chromosomes. If crossing over does not occur, the products are parental gametes. If crossing over occurs, the products are recombinant gametes. The allelic composition of parental and recombinant gametes depends upon whether the original cross involved genes in coupling or repulsion phase.
meiosis I - In meiosis, the chromosome or chromosomes duplicate (during interphase) and homologous chromosomes exchange genetic information (chromosomal crossover) during the first division, called meiosis I. The daughter cells divide again in meiosis II, splitting up sister chromatids to form haploid gametes. Gamete - a mature haploid male or female germ cell which is able to unite with another of the opposite sex in sexual reproduction to form a zygote. Zygote - a diploid cell resulting from the fusion of two haploid gametes; a fertilized ovum. Haploid - (of a cell or nucleus) having a single set of unpaired chromosomes. RNA - ribonucleic acid - Its principal role is to act as a messenger carrying instructions from DNA to ribosomes for controlling the synthesis of proteins. The Human Genome Project estimated that humans have between 20,000 and 25,000 genes, every person has two copies of each gene, one inherited from each parent.
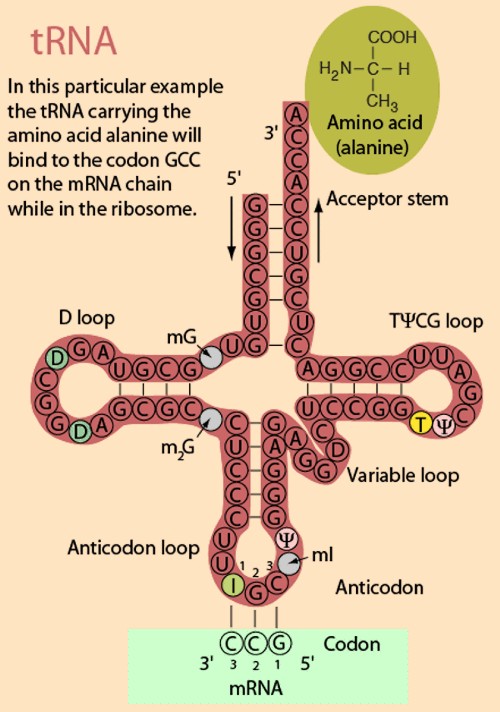
mRNA - Messenger RNA (mRNA) is a single-stranded RNA molecule that is complementary to one of the DNA strands of a gene. The mRNA is an RNA version of the gene that leaves the cell nucleus and moves to the cytoplasm where proteins are made. During protein synthesis, an organelle called a ribosome moves along the mRNA, reads its base sequence, and uses the genetic code to translate each three-base triplet, or codon, into its corresponding amino acid.
Scientists keep track of genes by giving them unique names. Because gene names can be long, genes are also assigned symbols, which are short combinations of letters (and sometimes numbers) that represent an abbreviated version of the gene name. For example, a gene on chromosome 7 that has been associated with cystic fibrosis is called the cystic fibrosis transmembrane conductance regulator; its symbol is CFTR.
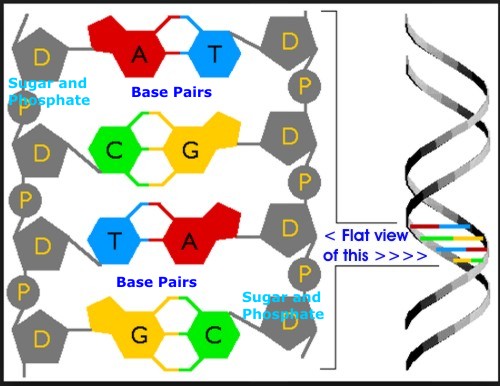
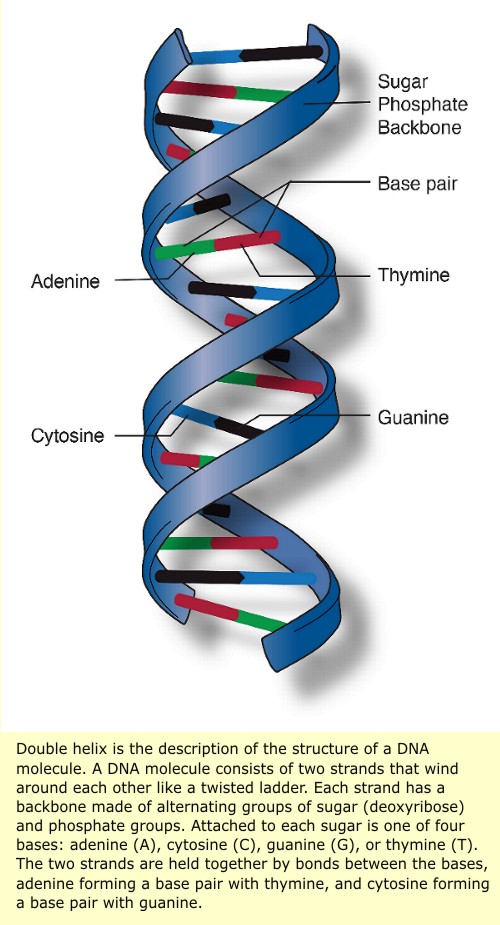
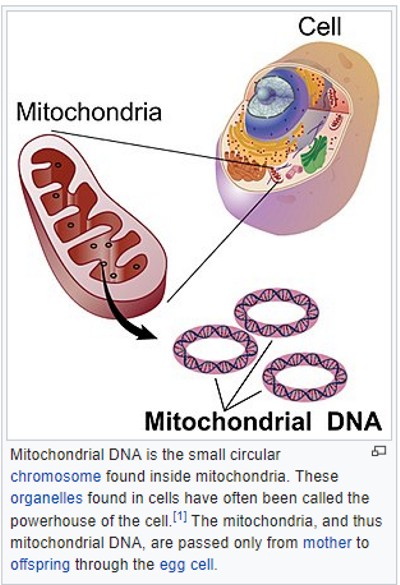
DNADNA, or Deoxyribonucleic Acid, is the hereditary material in humans and almost all other organisms. Nearly every cell in a person’s body has the same DNA. Most DNA is located in the cell nucleus (called nuclear DNA), but a small amount of DNA can also be found in the mitochondria (where it is called mitochondrial DNA or mtDNA). Mitochondria are structures within cells that convert the energy from food into a form that cells can use. The information in DNA is stored as a code made up of four chemical bases: adenine (A), guanine (G), cytosine (C), and thymine (T).
Human DNA consists of about 3 billion bases, and more than 99 percent of those bases are the same in all people. The order, or sequence, of these bases determines the information available for building and maintaining an organism, similar to the way in which letters of the alphabet appear in a certain order to form words and sentences. DNA bases pair up with each other, A with T and C with G, to form units called base pairs. Each base is also attached to a sugar molecule and a phosphate molecule. Together, a base pair, a sugar, and a phosphate are called a nucleotide. Nucleotides are arranged in two long strands that form a spiral called a double helix. The structure of the double helix is somewhat like a ladder, with the base pairs forming the ladder’s rungs and the sugar and phosphate molecules forming the vertical sidepieces of the ladder. DNA that actually codes for proteins cannot vary much without rendering the proteins ineffective. The four nucleotide bases that make up the backbone of DNA provide instructions for assembling the amino acids in proteins in a precise sequence: with each “Three-Base” group coding for a specific amino acid. If that DNA base sequence is altered (or "mutated"), the sequence of amino acids in the resulting protein can also be altered. As a result, because protein function derives from a specific amino acid sequence, the protein may not work.
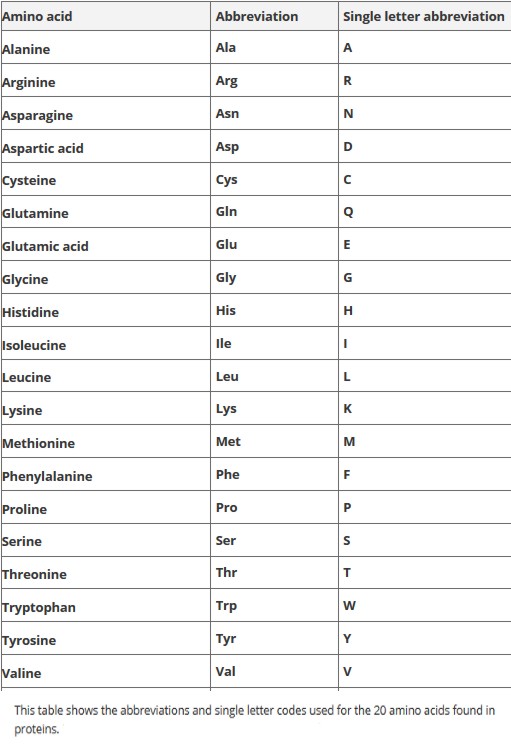
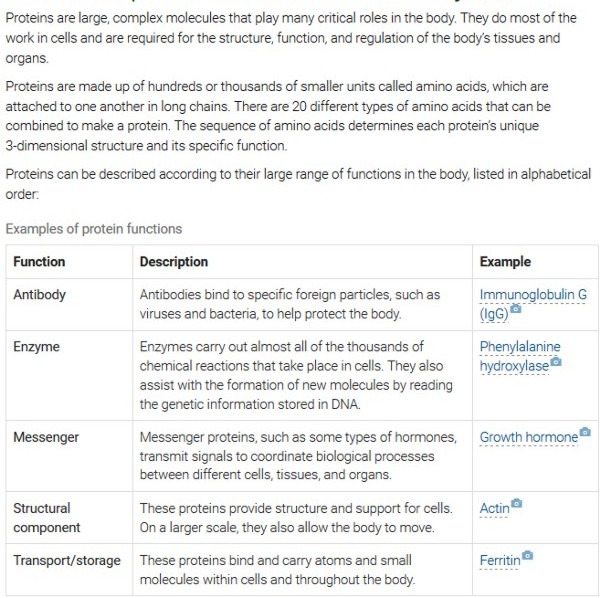
Amino Acids
Proteins
Think of DNA as the "Blueprint" for a house and Proteins as the steel, timber, bricks and mortar, from which the house will be built. A brick that is mostly sand instead of clay will crumble, and mortar with the wrong ratio of cement to aggregate will fail. Likewise, a protein with the wrong sequence of amino acids often won't function. (This analogy fails to capture the complexity of the DNA-protein system) because proteins are not only the "Bricks" and "Timber." Some also "READ" the "Blueprint" and SUPERVISE the building, others are the "Bricklayers" and "Carpenters" and still others “Maintain” and keep the house functioning after it is built.) “Non-functional” or missing proteins are the basis for many Genetic Diseases. DNA's ability to store - and transmit - information lies in the fact that it consists of two polynucleotide strands that twist around each other to form a double-stranded helix. DNA belongs to a class of molecules called the nucleic acids, which are polynucleotides - that is, long chains of nucleotides. The bases link across the two strands in a specific manner using hydrogen bonds: cytosine (C) pairs with guanine (G), and adenine (A) pairs with thymine (T). The double helix of the complete DNA molecule resembles a spiral staircase, with two sugar phosphate backbones and the paired bases in the centre of the helix. This structure explains two of the most important properties of the molecule. First, it can be copied or 'replicated', as each strand can act as a template for the generation of the complementary strand. Second, it can store information in the linear sequence of the nucleotides along each strand.
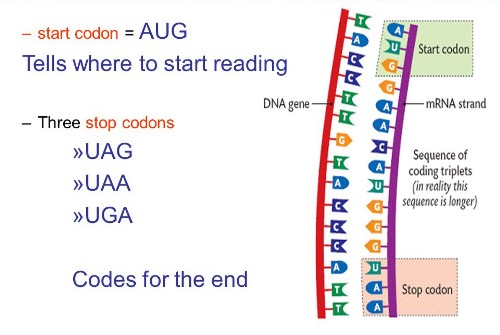
Codon - a sequence of three nucleotides which together form a unit of genetic code in a DNA or RNA molecule. Each amino acid can be coded for by more than one codon. For example, AGA and AGG both code for the amino acid arginine. A codon table sets out how the triplet codons code for specific amino acids.
Codon
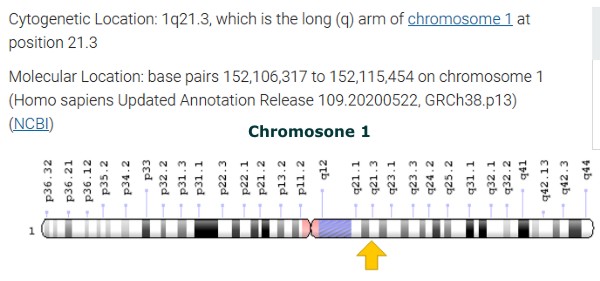
The DNA Double HelixThe pair of chains has a radius of 10 angstroms (1.0 nanometre: = one billionth of a metre (0.000000001 m). However a DNA polymer (a molecular structure consisting chiefly or entirely of a large number of similar units bonded together), can be very large and contain hundreds of millions, such as in chromosome 1. Chromosome 1 is the largest human chromosome with approximately 220 million base pairs, and would be 85 mm long if straightened.
DNA Base Pairs
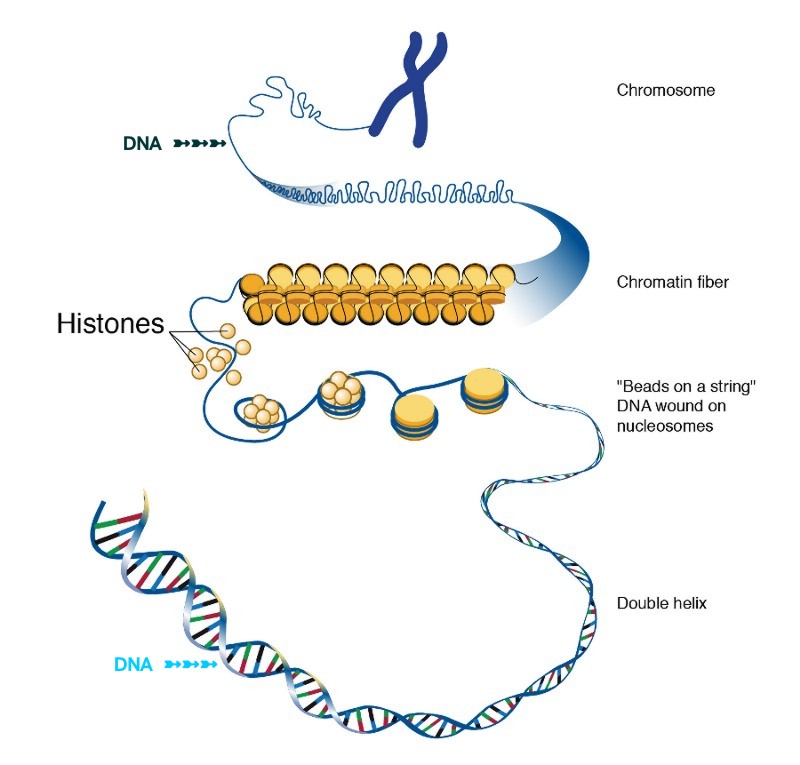
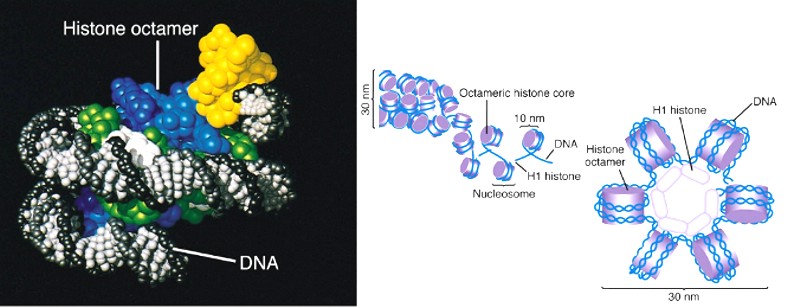
An important property of DNA is that it can replicate, or make copies of itself. Each strand of DNA in the double helix can serve as a pattern for duplicating the sequence of bases. This is critical when cells divide because each new cell needs to have an exact copy of the DNA present in the old cell. DNA and histone proteins are packaged into structures called chromosomes.
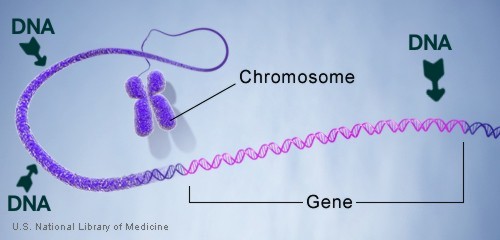
Chromosome
Each gene resides at a specific locus (location on a chromosome) in two copies, one copy of the gene inherited from each parent. As a simplistic example: When two Chinese mate, the child will look Chinese because all the genes are healthy and all the genes are the same. But if a Chinese and a White European mate, the children will look like some combination of the two, because the "Appearance" genes are not all the same. Gene copies, however, are not always healthy. When the copies of a gene differ from each other, as through deleterious mutation or failure: Then in this heterozygous condition, we call the two parts “Alleles” and the undamaged or un-mutated allele is dominant, and the organism’s appearance and function is normal. The damaged "other" allele has no noticeable effect on the organism’s appearance, and is called the “Recessive” allele. When BOTH alleles of a gene become recessive, then the gene cannot complete its assignment. As an example: many Black people have alleles of their “P” gene which are heterozygous and they look normal in every way: (The “P” gene controls the production of Melanin in the skin for protection from the Sun). But if TWO of these people with heterozygous alleles in their “P” gene MATE, then one or more, of their children will be an Albino. If two Albinos mate, there is only damaged or recessive “P” genes to inherit; therefore ALL of their children will be White. The trait for curly hair (which is the normal for humans) follows the same rules, two damaged or recessive allele’s of the "TCHH" gene means straight hair. Same for the genes which control eye color and hair color: (Blonde and Red hair is recessive, as is Blue, Green, and Gray eyes). Note: The trait for Curly/Kinky hair (which is the "Normal" for humans): is produced by two "Undamaged" TCHH genes. That means that "Curly Hair" is "ANCESTRAL" to Modern Humans. You might keep that in mind the next time you see the White mans depictions of ancient humans shown with "Straight" hair. HISTONES
Changes in the number or structure of chromosomes in new cells may lead to serious problems. For example, in humans, one type of leukemia and some other cancers are caused by defective chromosomes made up of joined pieces of broken chromosomes. It is also crucial that reproductive cells, such as eggs and sperm, contain the right number of chromosomes and that those chromosomes have the correct structure. If not, the resulting offspring may fail to develop properly. For example, people with Down syndrome have three copies of chromosome 21, instead of the two copies found in other people. Histone octamer
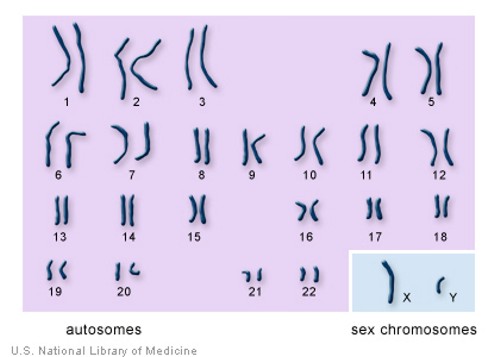
How many chromosomes do people have?
Chromosome 1Chromosome 1 is the designation for the largest human chromosome. Humans have two copies of chromosome 1, as they do with all of the autosomes, which are the non-sex chromosomes. Chromosome 1 spans about 249 million nucleotide base pairs, which are the basic units of information for DNA. It represents about 8% of the total DNA in human cells. It was the last completed chromosome, sequenced two decades after the beginning of the Human Genome Project.
The "X" ChromosoneThe X chromosome is one of the two sex chromosomes in humans (the other is the Y chromosome). The sex chromosomes form one of the 23 pairs of human chromosomes in each cell. The X chromosome spans about 155 million DNA building blocks (base pairs) and represents approximately 5 percent of the total DNA in cells. Each person normally has one pair of sex chromosomes in each cell. Females have two X chromosomes, while males have one X and one Y chromosome. Early in embryonic development in females, one of the two X chromosomes is randomly and permanently inactivated in cells other than egg cells. This phenomenon is called X-inactivation or lyonization. X-inactivation ensures that females, like males, have one functional copy of the X chromosome in each body cell. Because X-inactivation is random, in normal females the X chromosome inherited from the mother is active in some cells, and the X chromosome inherited from the father is active in other cells. Some genes on the X chromosome escape X-inactivation. Many of these genes are located at the ends of each arm of the X chromosome in areas known as the pseudoautosomal regions. Although many genes are unique to the X chromosome, genes in the pseudoautosomal regions are present on both sex chromosomes. As a result, men and women each have two functional copies of these genes. Many genes in the pseudoautosomal regions are essential for normal development. Identifying genes on each chromosome is an active area of genetic research. Because researchers use different approaches to predict the number of genes on each chromosome, the estimated number of genes varies. The X chromosome likely contains 800 to 900 genes that provide instructions for making proteins. These proteins perform a variety of different roles in the body.
The "Y" Chromosone
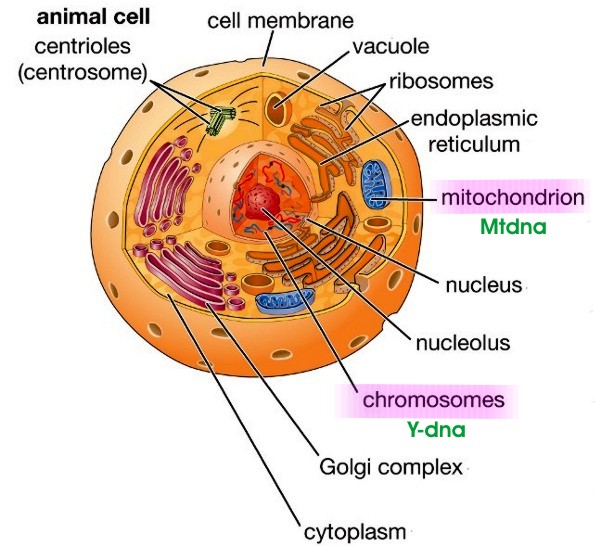
CellsCells are the basic building blocks of all living things. The human body is composed of trillions of cells. They provide structure for the body, take in nutrients from food, convert those nutrients into energy, and carry out specialized functions. Cells also contain the body’s hereditary material and can make copies of themselves. Cells have many parts, each with a different function. Some of these parts, called organelles, are specialized structures that perform certain tasks within the cell. Human cells contain the following major parts, listed in alphabetical order:
Cytoplasm - Within cells, the cytoplasm is made up of a jelly-like fluid (called the cytosol) and other structures that surround the nucleus. Mitochondria - Mitochondrial DNA (mtDNA) is the DNA located in mitochondria, cellular organelles within eukaryotic cells that convert chemical energy from food into a form that cells can use, adenosine triphosphate (ATP). Mitochondrial DNA is only a small portion of the DNA in a eukaryotic cell; most of the DNA can be found in the cell nucleus. Because mtDNA does not change as rapidly as nuclear DNA, and because it is not mixed with the father's (paternal) DNA, it leaves a clearer record of distant ancestry – although only through the mothers' (maternal ancestry). Nucleus - The nucleus serves as the cell’s command center, sending directions to the cell to grow, mature, divide, or die. It also houses DNA (deoxyribonucleic acid), the cell’s hereditary material. The nucleus is surrounded by a membrane called the nuclear envelope, which protects the DNA and separates the nucleus from the rest of the cell. Nuclear chromosomes discussed below. Plasma membrane - The plasma membrane is the outer lining of the cell. It separates the cell from its environment and allows materials to enter and leave the cell. Genetic CodeGenetic Code is the set of rules used by living cells to translate information encoded within genetic material (DNA or mRNA sequences of nucleotide triplets, or codons) into proteins. Translation is accomplished by the ribosome, which links amino acids in an order specified by messenger RNA (mRNA), using transfer RNA (tRNA) molecules to carry amino acids and to read the mRNA three nucleotides at a time. The genetic code is highly similar among all organisms and can be expressed in a simple table with 64 entries.
What holds cells together?Cell adhesion is the process by which cells interact and attach to neighbouring cells through specialised molecules of the cell surface. This process can occur either through direct contact between cell surfaces or indirect interaction, where cells attach to surrounding extracellular matrix, a gel-like structure containing molecules released by cells into spaces between them. Cells adhesion occurs from the interactions between cell-adhesion molecules (CAMs), transmembrane proteins located on the cell surface. Cell adhesion links cells in different ways and can be involved in signal transduction for cells to detect and respond to changes in the surroundings. Other cellular processes regulated by cell adhesion include cell migration and tissue development in multicellular organisms. Alterations in cell adhesion can disrupt important cellular processes and lead to a variety of diseases, including cancer and arthritis. Cell adhesion is also essential for infectious organisms, such as bacteria or viruses, to cause diseases.
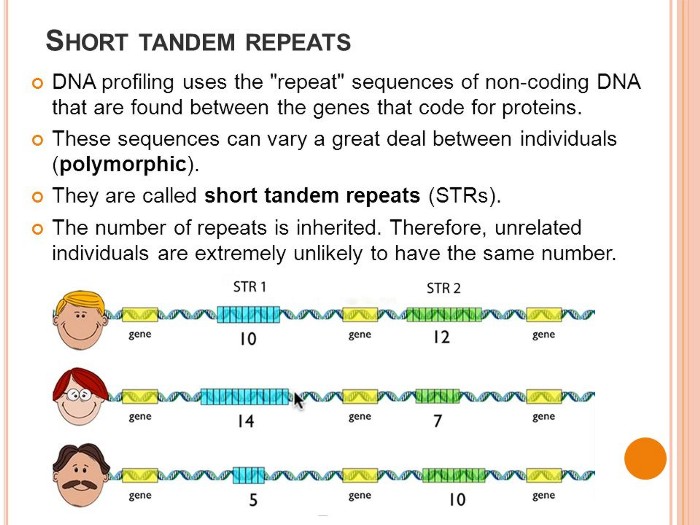
STRs (short tandem repeats)
Among the 3 million or so DNA bases that Do Not code for proteins are regions with multiple copies of short repeating sequences of these bases which make up the DNA backbone. These sequences repeat a variable number of times in different individuals. Such regions are called "variable number short tandem repeats," and they are the basis of STR analysis. A collection of these can give nearly irrefutable evidence statistically of a person's identity because the likelihood of two unrelated people having the same number of repeated sequences in these regions becomes increasingly small as more regions are analyzed. Autosomal chromosomes are those not involved in determining a person's gender, and STRs on these chromosomes are called autosomal STRs. Other STRs used for forensic purposes are called Y-STRs, which are derived solely from the male sex determining Y chromosome. Profiles based on autosomal STRs provide far stronger statistical power than profiles based on Y-STRs: because autosomal DNA is randomly exchanged between matched pairs of chromosomes in the PROCESS of making EGG and SPERM cells. That's how, with billions of humans on the planet, no two people who are not identical twins are exactly alike. Profiles based on Y-STRs are statistically WEAKER because only males have a Y chromosome and all males get theirs from their fathers, so all males in any paternal line have nearly identical Y chromosomes. Given enough Y-STRs, which scientists call loci, a Y-STR profile can offer substantial power to discriminate between individuals, but this type of profile is certainly not as powerful as an autosomal STR profile.
Single Nucleotide Polymorphisms (SNPs)
|
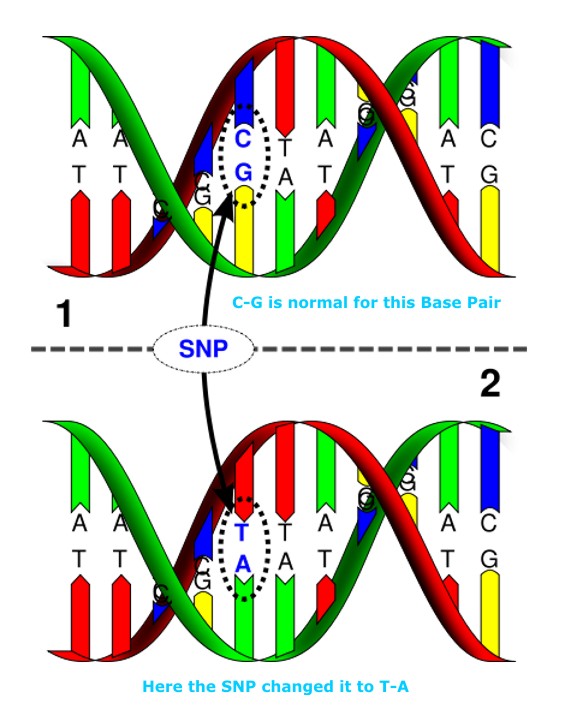 |
Single nucleotide polymorphisms, frequently called SNPs (pronounced “snips”), are the most common type of genetic variation among people. Each SNP represents a difference in a single DNA building block, called a nucleotide. For example, a SNP may replace the nucleotide cytosine (C) with the nucleotide thymine (T) in a certain stretch of DNA.
Single nucleotide polymorphisms, or SNPs, occur when a cell divides itself into TWO to make a NEW cell but does not properly copy its DNA, leaving the new cell with an incomplete set of genetic instructions. While not every SNP (or genetic “mutation”) creates an observable difference or symptom, specific SNPs can wreak havoc in a person.
SNPs occur normally throughout a person’s DNA. They occur almost once in every 1,000 nucleotides on average, which means there are roughly 4 to 5 million SNPs in a person's genome. These variations may be unique or occur in many individuals; scientists have found more than 100 million SNPs in populations around the world. Most commonly, these variations are found in the DNA Between GENES. They can act as biological markers, helping scientists locate genes that are associated with disease. When SNPs occur within a gene or in a regulatory region near a gene, they may play a more direct role in disease by affecting the gene’s function.
Most SNPs have no effect on health or development. Some of these genetic differences, however, have proven to be very important in the study of human health. Researchers have found SNPs that may help predict an individual’s response to certain drugs, susceptibility to environmental factors such as toxins, and risk of developing particular diseases. SNPs can also be used to track the inheritance of disease genes within families. Future studies will work to identify SNPs associated with complex diseases such as heart disease, diabetes, and cancer.
SNPs as a Measure of Genetic Similarity
DNA is passed from parent to child, so you inherit your SNPs versions from your parents. You will be a match with your siblings, grandparents, aunts, uncles, and cousins at many of these SNPs. But you will have far fewer matches with people to whom you are only distantly related. The number of SNPs where you match another person can therefore be used to tell how closely related you are. So says 23andMe, but the fact is there is not a reliable way to use SNPs for general identity purposes.
 |
 |
Tracing Human Origins
Y-DNA haplogroups are defined by the presence of a series of Y-DNA SNP markers. Each SNP represents a difference in a single DNA building block, called a nucleotide. Subclades are defined by a terminal SNP, that is, the SNP furthest down in the Y-chromosome phylogenetic tree. A person has many inherited SNPs that together create a unique DNA pattern for that individual.
Y chromosome (Y-DNA) and mitochondrial DNA (MT-DNA) studies have been used to support ideas about modern human origins. These DNA technologies exploit two types of genetic markers: the short tandem repeats (STRs), and single nucleotide polymorphisms (SNPs). The STRs are found on the Y chromosome (Y-STRs) and used exclusively for tracing male lines of heredity. The SNPs are found on the Y chromosome and in MT-DNA. They are used to trace male and female lines of heredity. The result of the test is a set of numbers, referred to as the haplotype, that represents the allele values of DYS markers (D for DNA, Y for chromosome, and S for segment) on a portion of the DNA. The haplotype is used to identify the haplogroup of an individual. Thus, the haplogroup represents a group of people who have inherited common genetic characteristics from the same most recent common ancestor (MRCA) going back several thousand years. All humans belong to haplogroups which are designated according to their Y-DNA and MT-DNA.
Because Y-chromosomes are passed from father to son virtually unchanged,
Males can trace their patrilineal (male-line) ancestry by testing their Y-chromosome.
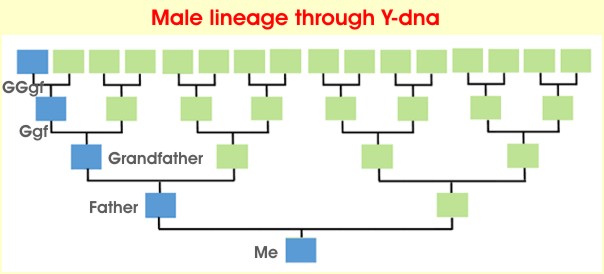 |
From ISOGG Wiki
A mitochondrial DNA test (mtDNA test) traces a person's matrilineal or mother-line ancestry using the DNA in his or her mitochondria. mtDNA is passed down by the mother unchanged, to all her children, both male and female. A mitochondrial DNA test, can therefore be taken by both men and women. If a perfect match is found to another person's mtDNA test results, one may find a common ancestor in the other relative's (matrilineal) "information table".
Mitochondrial DNA (mtDNA) is the small circular chromosome found in mitochondria. The mitochondria are organelles found in cells that are the sites of energy production. The mitochondria, and thus mitochondrial DNA, are passed from mother to offspring (male and female). But sons cannot pass along their mothers' mtDNA to their children. This is because mtDNA is transmitted through the female egg.
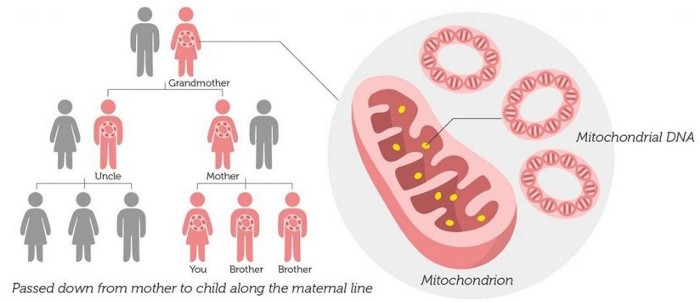 |
HOWEVER! Paternal transmission of mitochondrial DNA (mtDNA) may be possible, a new study suggests – contradicting the accepted view that it is passed on exclusively through maternal inheritance. The find, made by a team led by Taosheng Huang from Cincinnati Children’s Hospital Medical Centre, and Paldeep Atwal, from Mayo Clinic Hospital, Jacksonville, both in the US.
Mtdna Haplogroups
Wikipedia:
The hypothetical woman at the root of all Mtdna haplogroups (meaning just the mitochondrial DNA haplogroups) is the matrilineal most recent common ancestor (MRCA) for all currently living humans. The most recent common ancestor of modern human mtDNA is dated to ca. 230–150 kya. The emergence of haplogroup L1-6 by definition dates a later time, at an estimated 200–130 kya, possibly in a population in eastern Africa. Haplogroup L0 emerges from the basal haplogroup L1-6* somewhat later, at an estimated 190–110 kya.
Distribution
Putting aside its sub-branches, haplogroups M and N, the L haplogroups are predominant all over sub-Saharan Africa; L is at 96–100%, apart. It is found in North Africa, Arabian Peninsula, Middle East, Americas, Europe, ranging from low to high frequencies depending on the country.
Africa
With the exception of a number of lineages that returned to Africa from Eurasia after the out of Africa migration, all African lineages belong to haplogroup L. The "back-to-Africa" haplogroups including U6, X1 and possibly M1 have returned to Africa possibly as far back as 45,000 years ago. Haplogroup H, which is common among Berbers, is also believed to have entered Africa from Europe during the post-glacial expansion. The mutations that are used to identify the basal lineages of haplogroup L, are ancient and may be 150,000 years old. The deep time depth of these lineages entails that substructure of this haplogroup within Africa is complex and, at present, poorly understood. The first split within haplogroup L occurred 140–200kya, with the mutations that define macrohaplogroups L0 and L1-6. These two haplogroups are found throughout Africa at varying frequencies and thus exhibit an entangled pattern of mtDNA variation. However the distribution of some subclades of haplogroup L is structured around geographic or ethnic units. For example, the deepest clades of haplogroup L0, L0d and L0k are almost exclusively restricted to the Khoisan of southern Africa. L0d has also been detected among the Sandawe of Tanzania, which suggests an ancient connection between the Khoisan and East African populations.
If you have read the other parts of Realhistoryww, then you know the above about "back-to-Africa" is another fine example of the Albino Boys at Wikipedia in “full Delusion Mode” or “Full Lie Mode”, we are never sure which.
Mitotyping Technologies, LLC. A division of SoftGenetics.
The clear choice for Mitochondrial DNA analysis
Mtdna Basics
Mitochondrial DNA (mtDNA) provides a valuable locus for forensic DNA typing in certain circumstances. The high number of nucleotide polymorphisms or sequence variants in the two hypervariable portions of the non-coding control region can allow discrimination among individuals and/or biological samples.
Molecular anthropologists have been using mtDNA for three decades to examine both the extent of genetic variation in humans and the relatedness of populations all over the world. Because of its unique mode of maternal inheritance it can reveal ancient population histories, which might include migration patterns, expansion dates, and geographic homelands. Recently mtDNA was extracted and sequenced from a Neanderthal skeleton. These results allowed anthropologists to say with some conviction that modern humans do not share a close relationship with Neanderthals in the human evolutionary tree.
Advantages and Disadvantages
MtDNA has advantages and disadvantages as a forensic typing locus, especially compared to the more traditional nuclear DNA markers that are typically used. As mentioned above, mtDNA is maternally inherited, so that any maternally related individuals would be expected to share the same mtDNA sequence. This fact is useful in cases where a long deceased or missing individual is not available to provide a reference sample but any living maternal relative might do so. Because of meiotic recombination and the diploid (bi-parental) inheritance of nuclear DNA, the reconstruction of a nuclear profile from even first degree relatives of a missing individual is rarely this straightforward.
A Haplotype Sharing Method for Determining the Relative Age of SNP Alleles (2009)
André R de Vries 1 , Gerard J te Meerman
PMID: 19797909 DOI: 10.1159/000243154
Abstract
There are two aspects regarding the age of alleles that are relevant as indicators of the timing of mutational events. The first is to know which alleles are species-specific; the second is about the time of origin of species-specific alleles. Both aspects can be analyzed using haplotype-sharing methods, by using the length of shared haplotypes as a measure of the speed of coalescence to common ancestors. The availability of sequence data for closely related species makes it possible to infer the original SNP allele. The allele present in more than one species is the original allele. In general, original alleles are expected to be more frequent, because the cumulative effects of genetic drift determine the maximum frequency a new mutant can reach. The human species is relatively young, and founder effects are still observable as extended linkage disequilibrium. Coalescence to a single founder takes place in human populations over a time frame that is so small that original haplotypes spanning several markers are still observable in current high-density SNP genotyping arrays. We show here that the length of shared haplotypes surrounding alleles is an indicator of the relative ages of alleles, and it is applicable to original and species-specific alleles.
Copyright 2009 S. Karger AG, Basel.
This author produced no further data that we know of - just this abstract.
Wikipedia
Haplogroup A also known as A-V148 and A-CTS2809/L991 is a human Y-chromosome DNA haplogroup. It is the foundational haplogroup to all known patrilineal lineages carried by modern humans, and thus is the Y-chromosomal Adam.
Formerly also known as "clade I", bearers of extant sub-clades of haplogroup A are entirely found in Africa (or among descendants of recently moved African populations), in contrast with the descendant haplogroup BT (clade II-X) bearers of which participated in the Out of Africa migration of anatomically modern humans.
The most basal subclades of haplogroup A are, by age of divergence, "A00", "A0", "A1" (also "A1a-T") and "A2-T". Haplogroup BT, which is ancestral to all non-African haplogroups, is a subclade of A2-T.
The study of human Y chromosome variation through ancient DNA - Hum Genet. 2017; 136(5): 529–546.
A number of Y chromosome sequences covered in this review have been generated with shotgun sequencing approach. These include the four oldest genomes of individuals dated to late Pleistocene as well as a number of remains from Europe and Americas dated to the Holocene period. A substantial proportion of the European and Middle Eastern Neolithic and Bronze Age remains have been sequenced, however, with hybridization-based capture technique.
Because most personal genomes that have been annotated by ISOGG come from individuals of European or North American descent the capture enriched for ISOGG SNPs is best suited for the study of European Y chromosome diversity while being less efficient for the study of other regions. But also in Europe it should be noted that clades that have become infrequent or extinct over time due to extensive admixture or population replacement would have less chance to be recognised with the SNP-targeting capture approach.
The American Journal of Human Genetics - Volume 98, Issue 4, 7 April 2016
The Divergence of Neandertal and Modern Human Y Chromosomes
Sequencing the genomes of extinct hominids has reshaped our understanding of modern human origins. Here, we analyze 120 kb of exome-captured Y-chromosome DNA from a Neandertal individual from El Sidrón, Spain. We investigate its divergence from orthologous chimpanzee and modern human sequences and find strong support for a model that places the Neandertal lineage as an outgroup to modern human Y chromosomes—including A00, the highly divergent basal haplogroup. We estimate that the time to the most recent common ancestor (TMRCA) of Neandertal and modern human Y chromosomes is 588 thousand years ago (kya) (95% confidence interval: 447–806 kya). This is 2.1 (95% CI: 1.7–2.9) times longer than the TMRCA of A00 and other extant modern human Y-chromosome lineages.
This estimate suggests that the Y-chromosome divergence mirrors the population divergence of Neandertals and modern human ancestors, and it refutes alternative scenarios of a relatively recent or super-archaic origin of Neandertal Y chromosomes. The fact that the Neandertal Y we describe has never been observed in modern humans suggests that the lineage is most likely extinct. We identify protein-coding differences between Neandertal and modern human Y chromosomes, including potentially damaging changes to PCDH11Y, TMSB4Y, USP9Y, and KDM5D. Three of these changes are missense mutations in genes that produce male-specific minor histocompatibility (H-Y) antigens. Antigens derived from KDM5D, for example, are thought to elicit a maternal immune response during gestation. It is possible that incompatibilities at one or more of these genes played a role in the reproductive isolation of the two groups.
 |
There seems to be no meaning to a SNPs location relative to its haplogroup. Marker L1036 corresponds to A0b in the ISOGG table below. Marker L1058 seems to corresponds to the terminal marker of A0b. While marker L1075 corresponds to A0a1. Marker L896 corresponds to A0. Marker L979 corresponds to A0a. Which is all very interesting, but a way to uniquely identify people, it is not. |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
The Y Chromosome Consortium (YCC) developed a system of naming major Y-DNA haplogroups with the capital letters A through T, with further subclades named using numbers and lower case letters (YCC longhand nomenclature). YCC shorthand nomenclature names Y-DNA haplogroups and their subclades with the first letter of the major Y-DNA haplogroup, followed by a dash and the name of the defining terminal SNP. (example below: E-P147, E-M75).
Y-DNA haplogroup nomenclature is changing over time to accommodate the increasing number of SNPs being discovered and tested, and the resulting expansion of the Y-chromosome phylogenetic tree. This change in nomenclature has resulted in inconsistent nomenclature being used in different sources. This inconsistency, and increasingly cumbersome longhand nomenclature, has prompted a move towards using the simpler shorthand nomenclature.
Haplogroup E
Possible time of origin = 65,000 – 73,000 years ago.
Possible place of origin = East Africa or West Asia
Ancestor DE
Descendants E-P147, E-M75
Defining mutations - L339, L614, M40/SRY4064/SRY8299, M96, P29, P150, P152, P154, P155, P156, P162, P168, P169, P170, P171, P172, P173, P174, P175, P176
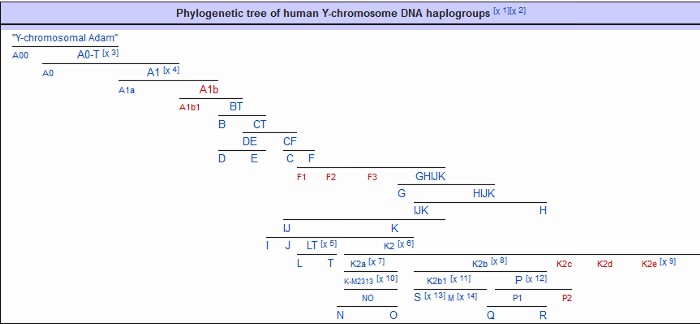 |
Haplogroups in Red are those for which there is no information yet.
Y-chromosomal data taken from a Neanderthal from El Sidrón, Spain, produced a Y-T-MRCA of 588,000 years ago for Neanderthal and Homo sapiens patrilineages, dubbed ante Adam and 275,000 years ago for Y-MRCA. The Y-chromosomal most recent common ancestor is the most recent common ancestor of the Y-chromosomes found in currently living human males.
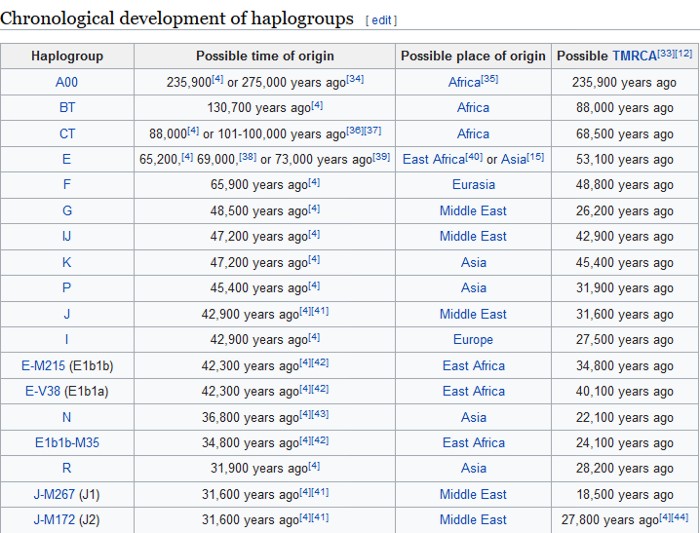 |
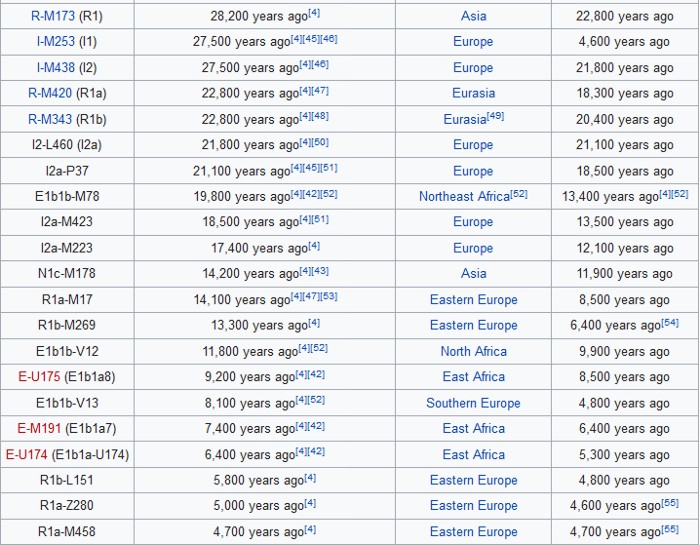 |
Note the screen print from ISOGG above, there are a zillion known SNPs, and more coming every day: and nobody knows what they really mean. As you can clearly see from all of those apparently meaningless numbers: There is no way to tell personal differences by DNA Haplogroup. As you can also certainly see it in the "World DNA Page" Which groups the worlds people by Y-dna haplogroup. Click for World DNA Page >>
In apparent frustration with the scientists being unable to provide definitive information on SNPs and Haplogroups, some families have taken to generating their own Y-DNA Haplogroup trees to fill the gap. The Marres family has produced a seemingly pretty good one - at least as good as any other.
Click here for the Marres Y-haplogroup tree >>>
_________________________________________________________________________________________________
OCA1 - is an autosomal recessive genetic disorder caused by mutations in the TYR gene located at chromosome band 11q14-q25.
OCA2 - The human OCA2 gene (P gene) is located on the long arm (q) of chromosome 15, specifically from base pair 28,000,020 to base pair 28,344,457 on chromosome 15.
OCA3 - is caused by a mutation in the tyrosinase-related protein 1, TYRP1, gene located on chromosome 9p23.
OCA4 - The gene responsible for OCA4, the SLC45A2 gene, is located on the short (p) arm of chromosome 5 at position 13.2.
OCA5 – The gene responsible for OCA5 has been located on chromosome 4 (4q24).
OCA6 - The gene responsible for OCA6, the SLC24A5 gene, is located on the long (q) arm of chromosome 15 at position 21.1.
OCA7 - The gene responsible for OCA7 is located at chromosome 10q23.3
Nappy or Straight Hair? The TCHH gene provides instructions for making a protein called trichohyalin. This protein is primarily found in hair follicles. Normal = Nappy hair: Mutated = Straight hair. See graphic below.
 |
Take the case of Harold George "Harry" Belafonte, Jr. (born March 1, 1927), he is an American singer, songwriter, actor and social activist. He was dubbed the "King of Calypso" for popularizing the Caribbean musical style with an international audience in the 1950s. Born Harold George Bellanfanti, Jr. at Lying-in Hospital in Harlem, New York: Belafonte was the son of Melvine (née Love) – a housekeeper of Jamaican descent – and Harold George Bellanfanti, Sr., a Martiniquan.
 |
 |
 |
Whatever Harry's DNA profile, his clearly "WHITE" granddaughter would also share it, therefore there is no uniqueness at this level. But it does serve to demonstrate how easily Humans slip from Perfect Black to Albinism and Back Again. (If David had mated with a Black Woman, his children would look like his father).
THERE IS NO WAY THAT AN ANCESTRY COMPANY CAN ACCURATELY TELL YOU WHERE YOUR PEOPLE CAME FROM.
STR analysis is a tool in forensic analysis that evaluates specific STR regions found on nuclear DNA. The variable (polymorphic) nature of the STR regions that are analyzed for forensic testing intensifies the discrimination between one DNA profile and another. Scientific tools such as FBI approved STRmix incorporate this research technique. Forensic science takes advantage of the population's variability in STR lengths, enabling scientists to distinguish one DNA sample from another.
This is ONLY good for telling if TWO PEOPLE ARE ALIKE: assuming they have the other in their database. But since the Worlds population is over 7 Billion, with over 5 Billion of them being Black: and these testing companies having barely 1 MILLION (mostly Albino samples for comparison), the chances are your results will be garbage.
A) Mitochondrial DNA is inherited through the maternal lineage. B) All female offspring inherit their mother's mitochondria, and therefore the same mitochondrial DNA. C) As a result, all female family members that share a maternal lineage would have the same mitochondrial DNA. D) Mitochondrial DNA can therefore be used to confirm or eliminate a person's relationship within a maternal line, but cannot be used to identify a specific individual.
The maternal inheritance pattern of mtDNA might also be considered problematic. Because all individuals in a maternal lineage share the same mtDNA sequence, mtDNA cannot be considered a unique identifier. In fact, apparently unrelated individuals might share an unknown maternal relative at some distant point in the past.
The ambiguity of Mtdna tests is why unscrupulous Albino and/or Mulatto scientists (Like those who did the Olmec Mtdna study in Mexico, choosing to do ONLY Mtdna testing: while claiming that samples were too damaged for Y-dna testing. (Pure Albino lie, Mexico is littered with Olmec remains). Got a bad one, go get another!
DNA studies and the origin of the Olmecs (2018), by Enrique Villamar Becerril
Quote: Long before Columbus, which led to the presence of black individuals in America. Over the years, the idea of the African origin of the Olmecs lingers in the minds of many people, since the same facial features that caused Melgar's amazement ended up being the constant in Olmec monuments.
The pioneering study of ADNMT carried out on Olmec individuals, one from San Lorenzo and the other from Loma del Zapote, resulted, in both cases, in the unequivocal presence of the distinctive mutations of the “A” maternal lineage. That is, the origin of the Olmecs is not in Africa but in America, since they share the most abundant of the five mitochondrial haplogroups characteristic of the indigenous populations of our continent: A, B, C, D and X. [end quote].
There are perhaps millions of Olmec remains in Mexico, yet this Charlatan uses only two?? Notice they haven't actually told us exactly what the Olmec Mtdna haplogroup really IS. Clearly this is not a scientific exercise, but rather an attempt by the Albinos and Mulattoes of Mexico to falsely claim lineage with the Olmec. Same as the Turks in the Middle East claiming lineage with Ancient Egyptians, Persians, Phoenicians, Arabs, etc.
How disturbing it is for a Black man to read nonsense like that from lying Albinos and Mestizos. This incompetent is suggesting that all Blacks in the Americas are from African Slaves, and the “Out of Africa” migrations didn’t happen: and what, the Olmec evolved in the Americas? Like all liars of this type, he is an ignoramus: Mtdna haplogroup “A” is abundant in Asia, as are all manner of Black people like the Olmec.
 |
Scientists compare all Mtdna sequences to the DNA sequence of one individual from Cambridge England known as the Cambridge Reference Sequence or “CRS”.This individual was chosen to serve as a comparison point for all other DNA sequences. This is similar to using a standard unit like a meter to measure the length of an object. The Cambridge Reference Sequence is the genome all scientists use as their standard for comparison; it is scientists’ “ruler”for comparing an individual’s DNA sequence to a standard.
The reference sequence belongs to European haplogroup H2a2a1. An alternative African (Yoruba) reference sequence has also been used sometimes instead of the Cambridge. It has a different numbering system with a length of 16,571 base pairs and represents the mitochondrial genome of one African individual.
Ancestry.com/AncestryDNA/RootsWeb/FindAGrave: claims 5 million people in its database. Wikipedia reports that they have just over one million actual genetic samples.
23andMe also claims 5 million people in its database - since they are much younger than Ancestry.com: Founded 2006 vs 1983, the odds are that their claim is also problematic.
GenCove has no published numbers.
The Genographic Project, launched on 13 April 2005 by the National Geographic Society and IBM, is a multi-year genetic anthropology study that aims to map historical human migration patterns by collecting and analysing DNA samples. Over 900,000 participants in over 140 countries have joined the project.
FamilyTreeDNA Database: they say - "Our databases are the most comprehensive in the field of Genetic Genealogy. As of May 11, 2018, the Family Tree DNA database has 965,088 records. Total numbers include transfers from the Genographic Project and resellers in Europe and Middle East."
The meaning of the term "Marker and DYS" below D = DNA <> Y = Y-chromosome <> S = (unique) segment numberIn this case Y-DNA segment 393, 39, 19, 391, 385, 426 return values of 12, 23, 12, 10, 16, 11 Currently marker DYS726 is the highest numbered marker studied. |
 |
No genome of the Black and Mongol Native Americans has ever been done, so NOBODY has any idea of what their genetic makeup actually looks like! In the United States the DNA test on the "Ancient Skeletons" is often Blocked by the Albino people whom the Albino government has falsely set up as the descendents of the Ancient Americans. Together with the contrived lie that the Blacks claiming tribal membership were actually the Tribes "SLAVES". The U.S. government and these Albinos/Mulattoes have managed to deny the actual "Full Blooded" Indians their rights and property.
|
 |
 |
 |
 |
Quote: It can tell you pretty reliably whether you are African or Asian or European.That is a LIE: as shown by scientific analysis, Europeans and Mongols have AFRICAN DNA, so how could there be a difference except for the Albino mutations.
Our page: "The Nonsense of White Genes" gives indepth explanations and examples.<< Click here for that page: >>Our page "Who are Americas Black People" is also a companion page to this page.<< Click here for that page: >> |
 |
 |
| Click for Realhistoryww Home Page |